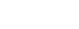


 Back to all articles
Back to all articlesWhat is it?
In 2015, Google started sending out notifications to webmasters via Google’s Search Console, advising them not to block CSS and Javascript files. This notification rolled out with little noise from the SEO community, as most were busy, trying to make their sites either mobile friendly or responsive as a part of Google’s Mobilegeddon Update, where Google started to give a ranking boost to those sites which were deemed viewable in mobile devices.
Why was it blocked?
JS and CSS files were originally blocked from Google’s index for many reasons. CMS software like WordPress, blocked a wide range of CSS and JS files automatically (including the whole wp-admin page), some third-party applications and plugins would block them, others thought that by blocking these files they were speeding up their site and also hiding vulnerabilities from potential hackers (this was a bit of a waste of time, as Google didn’t actually index these files anyway).
Why has it changed?
Many feel Google has come a long way over the last decade and has begun to operate a lot more human, i.e speech recognition, understanding the intent behind a search i.e most people searching for apple are looking for the brand, not the fruit. In their advance to become more human, having Google just crawl the text of the site can make be a lot different than what a user sees. For example, without styling and scripts, images and backgrounds aren’t loaded and menus have no navigation.
Also with Google bringing in the mobile-first index next year, more emphasis has been put on what output an actual user sees to decide where a website should rank, rather than just the amount of words on a page, or a number of times a keyword is used. This is backed up by Google itself which is advised that of the site owners that were sent notices that their sites were not mobile friendly, about 18.7% received notifications that they were blocking JS and CSS files.
Another reason why Google has changed the goalposts is down to the deceptive way JS and CSS files can present their information to Google and display different content to a user. For example, having the content appear first to Googlebot above the fold, whilst a visitor would actually see an advert of placeholder. Or in more manipulative ways it can be used to hide spammy SEO practices such as keyword stuffing and links from Google, or may even be used by a hacker to hide virus’s and injected code from the site owner!
Fetch & Render
It is interesting to see a site which is blocking CSS or JS from Google and see the different output that is shown to Google, then is shown to an actual website visitor. Within Google’s Search Console under Crawl > Fetch as Google you can see how your site looks under two options “fetch” and “fetch and Render”. “fetch” will just output the raw code on the page that Google sees, whilst “fetch and render” will display the output in a visual format with a comparison between what Googlebot sees and what a user sees. Here you can quickly highlight any issues which Google may not be currently indexing, for example, social media scripts or cookie notices.
How can I check it?
It amazes us still that may site owners still do not have Google Search Console (previously Google Webmaster Tools) setup on their sites. We won’t cover setting up Google Search Console here, but basically, apart from keeping up with the latest SEO news, this is the only way that you will find out if Google has an issue with your site, well apart from a loss of traffic or sudden drops in rankings.
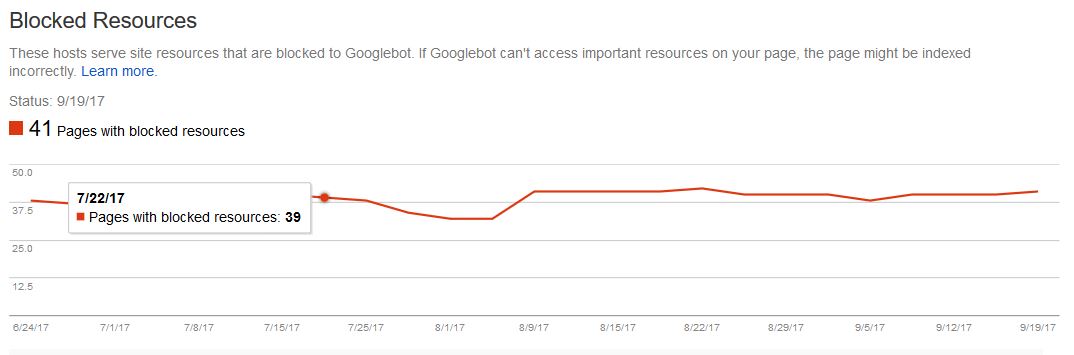
Whether you had a notification from Google or not (Google may no longer be sending these out), it is good housekeeping to see if you are actually blocking any of these resources. To do this go to your site in Google’s Search Console > Google Index > Blocked Resources and it will list any resources here. The truth is, there is no reason to block anything from Google.
You can also use crawling software such as DeepCrawl or Screaming Frog to detect any crawl issues with your site.
How Can Fix it?
These files are usually blocked by Google via the Robots.txt file which gives specific information to Google and other search engines about your site. (be very careful in editing this, If you are unsure or you could find yourself blocking your whole site from Google). To view your current robots.txt file either go to http://www.example.com/robots.txt or within Google’s search console go to crawl > robots.txt tester. Even if you didn’t put files in here direct, you may find CMS plugins and third-party applications can edit this file and block resources.
Just open the text file (you will need to find a copy of this, where you host your website) in any popular notepad application and take out any files that might be causing issues and re-upload back to the server. You will then need to re-fetch the robots.txt file via Google’s Search Console and check blocked resources again.